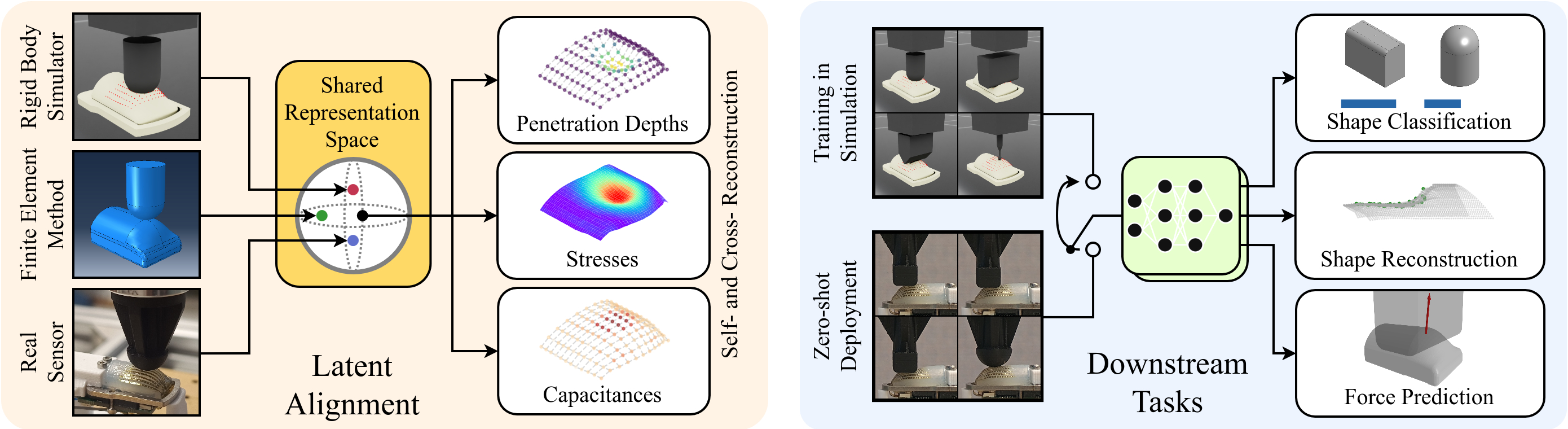
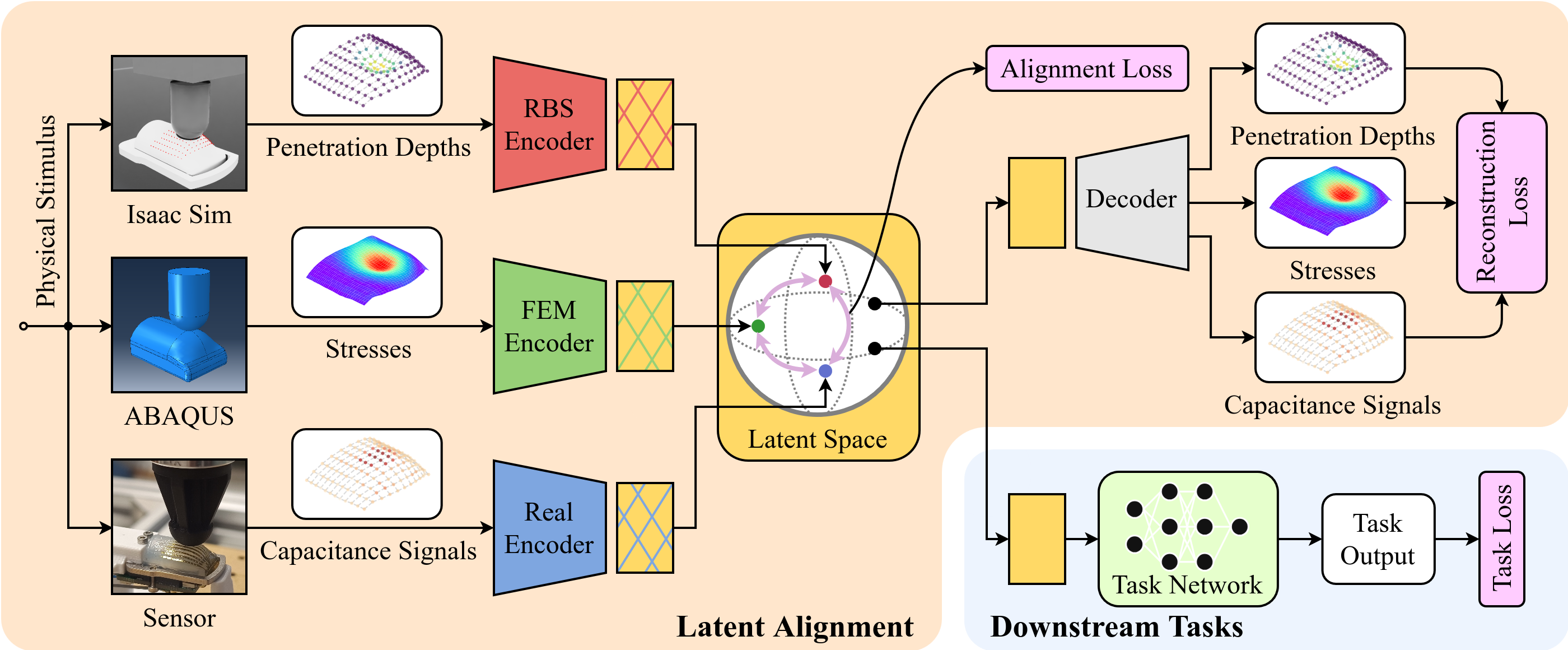
Tactile sensing provides direct measurements of contact interactions that are essential for robotic manipulation. However, current simulators lack the fidelity to faithfully model the complex deformation and transduction mechanics of tactile sensors, severely hindering sim-to-real transfer in robot learning pipelines. To address this challenge, we propose a multi-modal representation learning framework that aligns heterogeneous tactile modalities within a shared latent space, eliminating the need for accurate raw-signal simulation while preserving relevant contact information. Our approach employs modality-specific encoders to project diverse tactile observations, such as simulated penetration depth and real-world capacitance, into a common embedding space. The model is trained using self- and cross-reconstruction objectives alongside contrastive alignment, encouraging modality-invariant yet information-rich representations. We evaluate the learned embeddings on indenter shape identification, force prediction, and geometric reconstruction tasks, training exclusively in simulation and testing directly on real sensor measurements. Our results demonstrate zero-shot sim-to-real transfer across physically dissimilar representations. Furthermore, incorporating multi-physics simulation modalities yields more informative embeddings that transfer across diverse downstream tasks, demonstrating a 16.7% reduction in force prediction error and a 45.8% reduction in shape reconstruction error. Finally, we release an efficient Warp-based implementation of a penalty-based tactile simulation model for Isaac Lab, enabling scalable tactile data generation.
@inproceedings{joarder2026tactspace,
author = {Joarder, Arunim and Bhardwaj, Arjun and Zurbrügg, René and Mittal, Mayank and Püntener, Florin and Bielefeldt, Sira and Roman, Cosmin and Patil, Vaishakh and Hutter, Marco},
title = {TactSpace: Learning a Physics-enriched Shared Latent Space for Tactile Sim-to-Real Transfer},
booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
year = {2026},
note = {Accepted},
}